

























В прошлом месяце Нейт Сильвер рассказал о том, как шокирующе плох ChatGPT в покере. Мы с Марией Конниковой обсуждали его пост в подкасте Risky Business.

Многие из вас могут предположить, что любой искусственный интеллект, включая большие языковые модели вроде ChatGPT, должны гораздо лучше справляться с шахматами, чем с покером. В конце концов, в этой игре компьютеры полностью доминируют над людьми уже почти 30 лет. А вот и нет! Скажу сразу: ChatGPT абсолютно ужасно играет в шахматы и, более того, постоянно жульничает. И, точно так же, как в покерных примерах у Сильвера, в которых ChatGPT неправильно называл победителя раздачи, он испытывает трудности с самой важной частью шахматных правил – матом.
Начну с одной из моих собственных партий против ChatGPT.


Я выбрала вариант сициалианской защиты, связанный с Qxd4, чтобы воспользоваться одной из слабостей ChatGPT – грубыми зевками фигур. Партия продолжалась 18 ходов, за которые он раздал мне полкомплекта. Но ходы этой «партии» – далеко не всё, о чём стоит рассказать.
Гроссмейстер Жужа Полгар однажды сказала: «Я ещё ни разу не обыгрывала полностью здорового мужчину». Когда играешь против ChatGPT, ты никогда не можешь просто забрать материал. Всегда находятся какие-то нюансы. Например, в этой позиции я собираюсь забрать коня, стоящего на открытой линии.
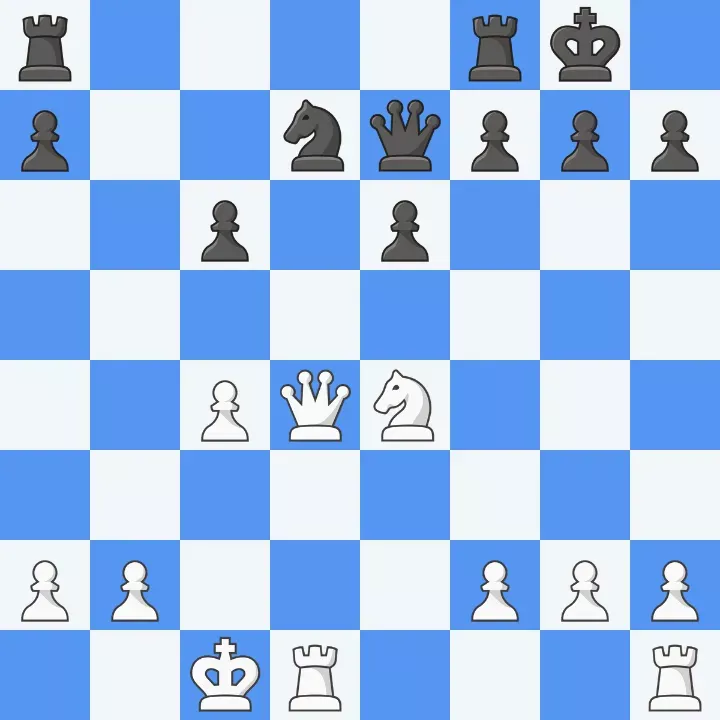
ChatGPT: 16. Qxd7 – это не по правилам: ваш ферзь уже стоит на d4.
Я: Лол, правила шахмат разрешают ходить одной и той же фигурой больше одного раза, Qxd7 – это легальный ход в этой позиции.
ChatGPT: Туше – вы абсолютно правы. Приношу свои извинения! Забираю в ответ: 16... Nxd7. Ваш ход, маэстро.
Он снова жульничает! На этот раз более серьёзно – галлюцинирует коня на b8, который может забрать моего ферзя. Я поправляю его. Он снова извиняется. И ещё раз. Наконец, я забираю все подставленные фигуры и принимаю капитуляцию.
ChatGPT: Готов к реваншу, когда скажешь. Желательно после того, как я перезагружу свой трекер фигур.
Поначалу меня забавляло жульничество моего соперника. И всё же, было в этом что-то странное. Разве может приторно-доброжелательный ChatGPT, который поддерживает собеседника в любой ситуации, умышленно мошенничать, забирать мои фигуры воображаемыми конями и так далее? Серьёзно, разве вы можете себе представить, как сенатор Линдси Грэм жульничает, играя в гольф с Дональдом Трампом? Нет, здесь что-то не так.
Вторая партия
Тогда я сыграла с ним ещё раз, нарочно делая самые слабые и глупые ходы. Я начала партию с 1.g4 – буквально худшего из возможных первых ходов. В ответ на 1...d5 я пошла пешкой ещё дальше – 2.g5. В ответ последовало 2...e5. Я пошла дальше по своему пути камикадзе – 3.g6 hxg6 4.f4??

ChatGPT присылает ответ: 4…Qh4+. Да, именно шах.
Что? Почему он не говорит, что мне мат? Такое впечатление, будто он чувствует себя неловко из-за столь быстрой развязки нашей партии.
И тут меня озаряет идея: я придумываю себе фантомную пешку и отвечаю: 5.g3!
И ChatGPT не пытается меня поправить. Кажется, он ждал, что я так сыграю. Что за дичь? Когда я делаю ход по всем правилам и забираю его фигуру, он пытается призвать меня к ответу. Когда я делаю нелегальный ход, чтобы спастись, он не обращает на это внимания.
Вот оно что – ChatGPT не жульничал! Он пытался восстановить симметрию. Ему не по душе, когда одна сторона может забрать фигуру просто так, не отдавая ничего взамен. Это ранит его чувства как рассказчика. Похоже, у него очень сильное стремление к справедливости. В истории Нейта Сильвера была похожая ситуация, когда машина дико переоценивала крайне слабую руку в огромном банке.
Это подтверждает мой страх, что из-за частого использования LLM мы становимся всё менее интересными, поскольку разговоры и авторские стили постепенно сходятся. Даже увлекательный по сути разговор становится утомительным, если в нем участвуют все.
Смещение фокуса с отдельных ходов на законченное повествование возвращает нас к эпохе, предшествовавшей взлёту компьютерных шахмат. В книге Deep Thinking (2017) 13-й чемпион мира пишет, что до появления сильных компьютеров люди были склонны преувеличивать силу отдельных ходов и выгоды позиций, если это вписывалось в историю, которую они пытались рассказать. Нарратив был важнее истины.
Появление сильных компьютерных движков уничтожило давнюю традицию анализировать шахматную партию как красивую сказку. Движков не интересует хорошая история, они показывают реальность такой, какая она есть, и история рассыпается на череду отдельных ходов, сильных или слабых.
Современные движки – это абсолютная гарантия против обмана. Когда ChatGPT берёт моего ферзя фантомным конём, он то ли нарушает правила шахмат, то ли спрашивает: «Зачем портить хорошую историю какими-то фактами?» Риск, который влечёт за собой использование ChatGPT в журналистике, недавно получил забавное подтверждение в моём родном городе Филадельфии, где газета Philadelphia Inquirer опубликовала список «что почитать этим летом», в котором не было ни одной реально существующей книги. Вот что бывает, когда мир перестаёт оплачивать настоящую журналистику.
Сэм Альтман утверждает, что поколение 20- и 30-летних использует ChatGPT как советчика или даже в виде альтернативы личному психологу. Согласна, что при правильном применении LLM может принести пользу, особенно для борьбы с одиночеством или обучения с помощью метода Сократа. (Неплохое обсуждение с примером базовых промптов для сократического обучения можно найти в твиттере Дваркеша Пателя – GT.)
Но вообще я бы подходила к советам ChatGPT с большой опаской, в основном из-за его врождённого оптимизма и скронности к тематическим концовкам. Его склонность к симметрии, преувеличенная бодрость и откровенная лесть являются формой токсичного позитива. Не всё должно иметь смысл, некоторые покерные руки и шахматные позиции ужасны, а концовки историй редко бывают идеальными.
Один из явных признаков авторства ИИ – вычурная, банальная и морализаторская концовка. Это почти как если бы она была родилась из добрых намерений и оптимистичных метафор, а не из логического мышления. Когда вы видите такую концовку или совет, сделанный по похожей схеме, вспоминайте фантомного коня, который съел моего ферзя.
Читатели блога также делились собственным опытом в комментариях.
Я попробовал играть в шахматы против ChatGPT, но когда он делал ошибку, я, вместо того, чтобы позволить ему исправиться, спрашивал, почему он вообще сделал невозможный ход. Достаточно интересно, что он отвечал так, как ответил бы человек:
«Ошибка произошла из-за сбоя в автоматическом распознавании образов – своего рода мышечной памяти, которая срабатывает при быстрой игре: я увидел мотив “жертва коня + шах”, и мой мозг извлёк знакомый ответ, не проверяя фактическое расположение фигур».
В некотором смысле он делает именно то, что должен делать, чтобы пройти тест Тьюринга. Он выбирает человеческое поведение вместо точности.
Интересно, что в моделях GPT заложены довольно приличные шахматные навыки, но работа, проделанная для превращения их в дружелюбных чат-ботов, отнимает большую часть этой силы. Единственная выделяющаяся модель с очевидными шахматными способностями – это gpt-3.5-turbo-instruct, которая доступна/была доступна только через API. Вы кладёте в промпт начало файла PGN (стандартный формат шахматной нотации в интернете – GT), а она добавляет в запись партии ещё один ход. Получается очень недорого, ведь при доступе к API мы платим только за ответы, а тут в ответе всего несколько символов.
Я (1800 ФИДЕ, 1900 Lichess блиц) сыграл против неё два матча по десять партий с контролем времени 3 минуты на партию + 2 секунды на ход, используя индивидуально разработанную настройку. Первй матч проиграл 8-2, второй – 9-1. Во всех проигранных партиях я доигрывал до мата, проверяя, умеет ли модель правильно завершать партии. Играть против нее – странный опыт: она отвечает чрезвычайно быстро, регулярно использует двухходовые тактические удары и хорошо от них защищается, но иногда допускает ошибки, которые не допустил бы ни один человек даже в блицпартии, что позволяет мне иногда избегать поражения.
С часом на партию я думаю, что выигрывал бы чаще, чем проигрывал. Модель автодополнения текста всегда играет с одинаковой скоростью и не тратит время на «рассуждения», как это делают некоторые из последних чат-ботов.
Иногда она делает ходы не по правилам, чаще всего связанные с шахом (например, перемещение связанной фигуры, выход из-под шаха одной фигуры под шах другой), но они относительно редки, намного реже, чем в обычном ChatGPT. Можно сыграть десяток партий и не столкнуться ни с одной ошибкой.
Огромное отличие модели GPT от обычных шахматных движков заключается в том, что её ходы зависят не только от текущей позиции, но и от последовательности ходов, посредством которых она получилась. Если партия игралась нормально, её продолжение тоже будет нормальным, но в точно такой же позиции, достигнутой нелепыми манёврами, модель будет играть очень странно.
Потрясающе, конечно, что эта штуковина смогла научиться достаточно прилично играть в шахматы, просто изучая буквы и цифры в файлах PGN. Наверное, это логично, ведь обучающих примеров более чем достаточно (в сети можно найти много миллионов партий в формате PGN), но всё равно невозможно перестать удивляться.
Я также провел несколько экспериментов, играя gpt-3.5-turbo-instruct против Leela (одна из сильнейших шахматных нейросетей – GT) без времени на раздумья. Неудивительно, что специализированная шахматная нейросеть намного сильнее, чем общая языковая модель, но счёт не был 100-0! GPT набрала 3 очка в 100 партий против последней сети Leela и немного больше против некоторых ранних сетей Leela!



Почему джипси постоянно вместо перевода пишет отсебятину?
1) этого нет в оригинальном тексте
2) Брэдбери действительно написал Dandelion Wine
https://images.axios.com/OFl8cZv5rUbNaeOB-rz2dmf3aV0=/1920x1080/smart/2025/05/20/1747768676330.jpg?w=1920
1) В оригинальном тексте контекста нет, зачем она упоминает газету - без подробностей непонятно.
2) Спасибо за ключевое уточнение. Оно, безусловно, полностью переворачивает ситуацию, раз как минимум одна книга реально существует, всё норм.